AI in DevOps: How to Manage Infrastructure with Agents
Production environments are complex. During the early days of infrastructure, the focus was on automating the deployment process. However, as systems have grown to far more complex systems. Between microservices, container orchestrators, multi-region deployments, and a ton of security and compliance requirements, the sheer amount of work required to manage production environments has become overwhelming. Additionally due to rise of coding agents, developers are producing more code than ever before. People are vibe coding, means they are writing code without actually writing code. This is all gonna land hot in production. It increases the backlog of work for DevOps teams who are already stretched thin.
This is good problem to solve but we really need a good counterbalance to this problem.
So how can AI agents help?
First I want address what is an agent? Agent is basically LLM in a loop + tools. Given a task an agent can reason in loop and use all the given tools to solve the problem as they fit. The rest is elbow grease, which is the glue that holds everything together. It’s the integration of tools, the persistent memory, and the iterative learning that transforms model into an agent.
These models are incredibly powerful now and biggest moat lies in the model itself. The reasoning is the brain of an agent.Now agents can solve the complex problem due to advancements in reasoning capabilities in models. Reasoning models are designed to handle complex problems by simulating human-like thought processes. The model is encouraged to think step-by-step, breaking down a problem in series of logical steps before arriving at a final answer. This is particularly useful for infrastructure tasks, which requires thinking towards multiple directions, use a lot of different tools, and needs the full context of the state of the system to make decisions.
So, how it all comes together? How can AI agents help DevOps teams manage production environments more effectively?
Production systems generate a lot of events & data like alerts, logs and metrics. We as infrastructure engineers are used to use a lot of different tools to deal with this data to solve problems. We use monitoring tools and infrastructure as code to see the state of the system, we use logging tools to see what happened, we use alerts to track the issues. An agent can reason through all of this data, utilizing given set of tools to solve variety of problems. tool is what makes an agent powerful. Given all the tools available, an agent can solve problems like incident response, resource management, cost optimization, security and compliance, and more.
As discussed earlier, agent needs to have all the required context to solve the problem. It doesn't just come from logs and metrics it comes from this complex graph of relationships in the organization. Who deployed what code, when, and why? all the slack threads where decisions are made. All the commits and PRs. Agent need to maintain this knowledge graph to be able to get context about the system.
Now once the alert is triggered, agent can use the context from the knowledge graph to reason through the problem. It generates many hypotheses and steps to validate them. It can use the tools available to it to validate the hypotheses and move in the right direction.
It is like the graph of thoughts that the agent has, it creates a tree of hypothesis. It uses the tools to decide which branch to take next and rule out bad hypotheses. It keeps on iterating through the tree until it final solution is found. Thanks to deterministic nature of the infrastructure, we can decide and terminate the reasoning process when we have enough confidence in the solution.
Example: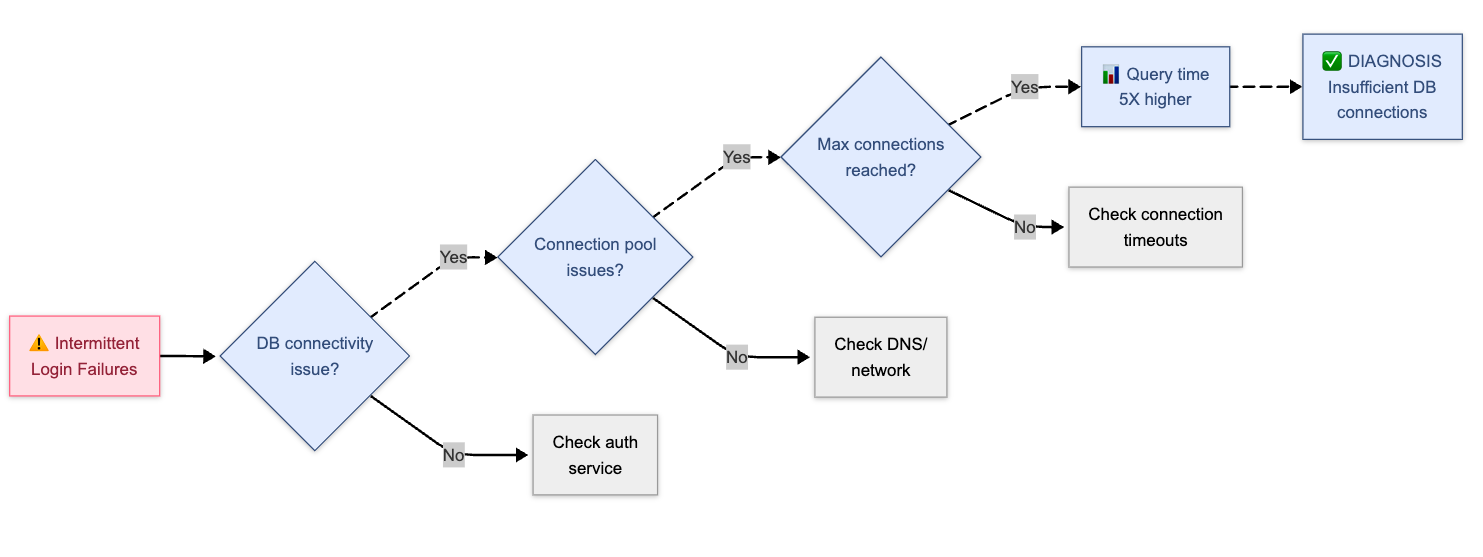
This is different from how agent would do content generation. In content generation, the agent would not have a terminal state due to the subjective nature of the task. That's why it works so well for infrastructure tasks.
Once the agent solves to the problem, it remembers it. It can store the steps taken, the hypotheses generated, and the final solution in the leanings memory. This way, the agent can learn from the experience. As it solves enough problems it gets smarter and smarter over time due to large memory. While the models keep on getting better, the agent keeps on getting better too at solving complex tasks.
Another biggest line of things we do in DevOps is to manage the resources. An agent can help a lot with this. We use different tools to get the information we need about the resources. Now as we already have the knowledge graph, the agent has enough context of the system that it can use it to answer questions about the resources.
For example: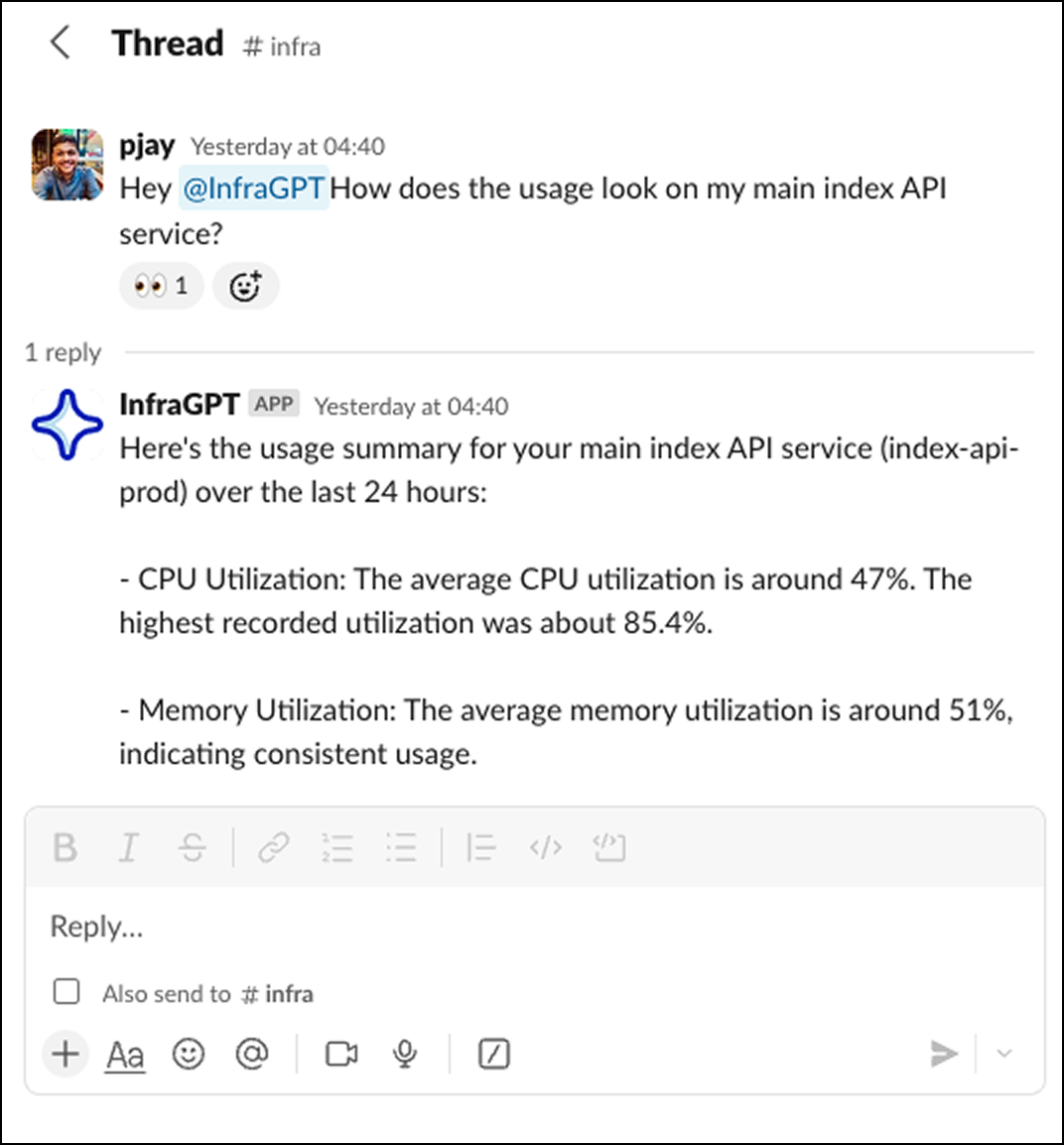
One of the most common use case for agents is code generation and with the infrastructure context it can generate runbooks, scripts, and even do drift updates in IaC configs.
The drift updates is very annoying thing for us to manage. Drift happens when someone manually tweaks resources outside terraform or any other IaC. The agent constantly monitors the desired-vs-actual state, and if it spots a deviation, ex. someone changed a load balancer rule, it can raise a PR with the changes.
Once we have our IaC configs update to date, it can help us doing infra cost calculations much earlier as we can combine the IaC configs with the pricing APIs to get the cost of the resources. We will know cost impact on every PR and every change we make to the infrastructure.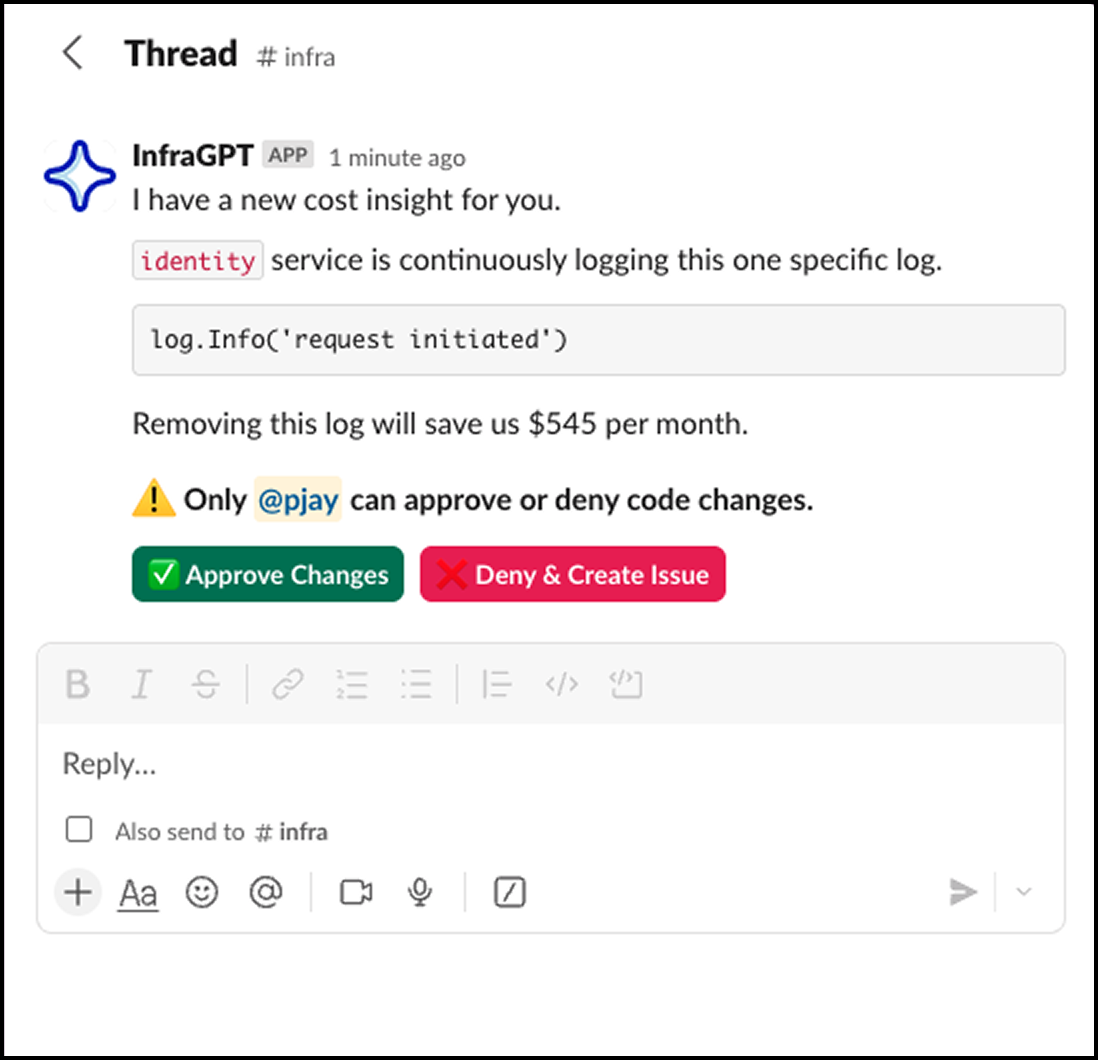
Security and compliance often feel like a never-ending checklist: “We need to rotate keys, audit logs, patch OS versions, review user privileges…” Again, agents can help here as they can continuously monitor the security posture of the infrastructure. Infant we can even run automated vulnerability assessments using the agent.
Agent can have access to vulnerability scanners and CVE databases, it can continuously evaluate the entire estate. For example, when it finds a high-severity CVE affecting currently deployed Kubernetes version it can raise an alert with PR to terraform config to update the version.
Recently, Sean Heelan a security researcher found a zero day vulnerability in linux kernel using OpenAI's o3 model. He ran the crafted prompts 100 times. o3 found his first, known vulnerability 8/100 times - but found the brand new one in just 1 out of the 100 runs it performed with a larger context.
While we discussed how these agents are so powerful in solving the infrastructure problems, we also need to measure the success.
We should keep track of the metrics specific to the category where we are using the agents. like: MTTR Reduction. Are incidents getting resolved faster (often without waking anyone up)? Cost Savings. Are your monthly cloud bills consistently dropping? Deployment Frequency. Can you push changes safely and more often, thanks to reliable pipelines? Team Satisfaction. Are you seeing fewer frustrated Slack messages at 2 AM? Are engineers focusing on higher-value work? Security Posture. Are critical vulnerabilities fixed within hours, not days?
These metrics will help us understand the impact of the agents on the infrastructure and how they are helping us manage the production environments.
Over time, this changes the shape of work. Agent will become the default.
Most organizations won't adopt this all at once. It can start using agent around the cost optimization and move towards incident response.
Once we start using agents it helps us focus on higher order engineering problems While automating the repetitive, tedious parts.
Last week I gave a talk at Kubernetes User Group in Bangalore about this topic. Here are the slides if you want to check it out.


